Chapter 21. Model Diagnostics and Empirical Credibility
A practical framework for evaluating whether regression results are believable.
Chapter purpose
Estimating a regression model is relatively easy. Determining whether the results are trustworthy is much more difficult.
Applied economists rarely accept regression output at face value. Instead, they examine assumptions, evaluate model fit, inspect residuals, test alternative specifications, and assess whether the estimated relationships are economically sensible.
This process is known as model diagnostics.
In this chapter, we bring together many of the ideas introduced throughout the course and learn how economists evaluate the credibility of empirical results.
Applied question
Can we trust the estimated relationship between fertilizer use and crop yield?
Suppose a researcher estimates the following model:
[ Yield_i = _0 + _1 Fertilizer_i + u_i ]
The coefficient on fertilizer is positive and statistically significant.
Does this automatically mean the result is credible?
Not necessarily.
Before drawing conclusions, we should evaluate the quality of the model.
Economic background
Empirical research is not simply about obtaining significant coefficients.
Researchers must consider questions such as:
Is the model correctly specified?
Are the assumptions reasonable?
Are there unusual observations?
Are results sensitive to alternative specifications?
Do the estimates make economic sense?
Good empirical work combines statistical evidence with economic reasoning.
Key idea
A useful regression model should satisfy two conditions.
Statistical credibility
The model should be consistent with the assumptions underlying regression analysis.
Economic credibility
The estimated relationships should be sensible from an economic perspective.
A statistically sophisticated model that contradicts basic economic logic is not convincing. Likewise, a theoretically appealing model that fails basic diagnostic checks should be interpreted cautiously.
A diagnostic framework
Whenever you estimate a regression model, ask five questions:
Do the coefficients make economic sense?
Are the coefficients statistically significant?
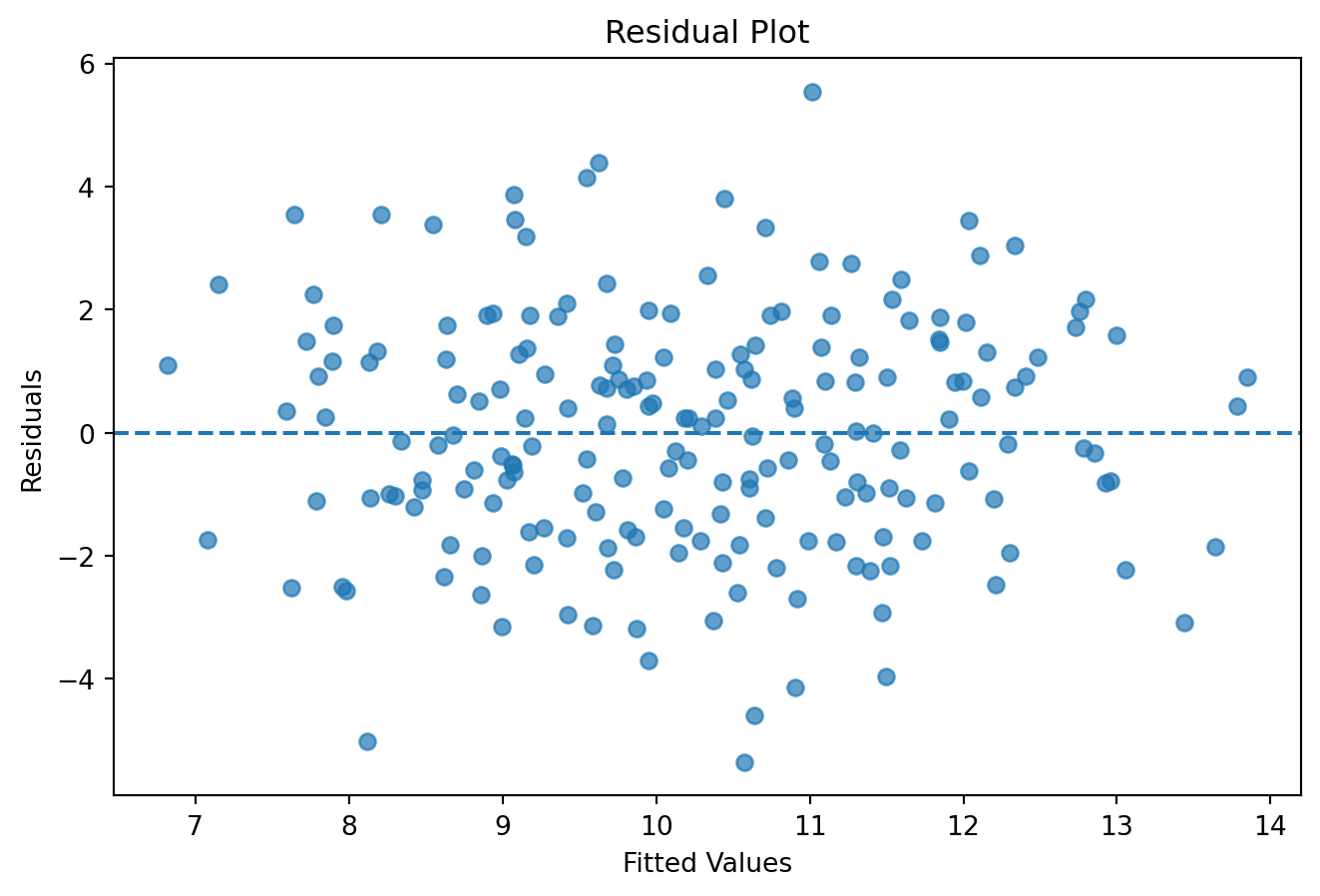
Do the residuals behave reasonably?
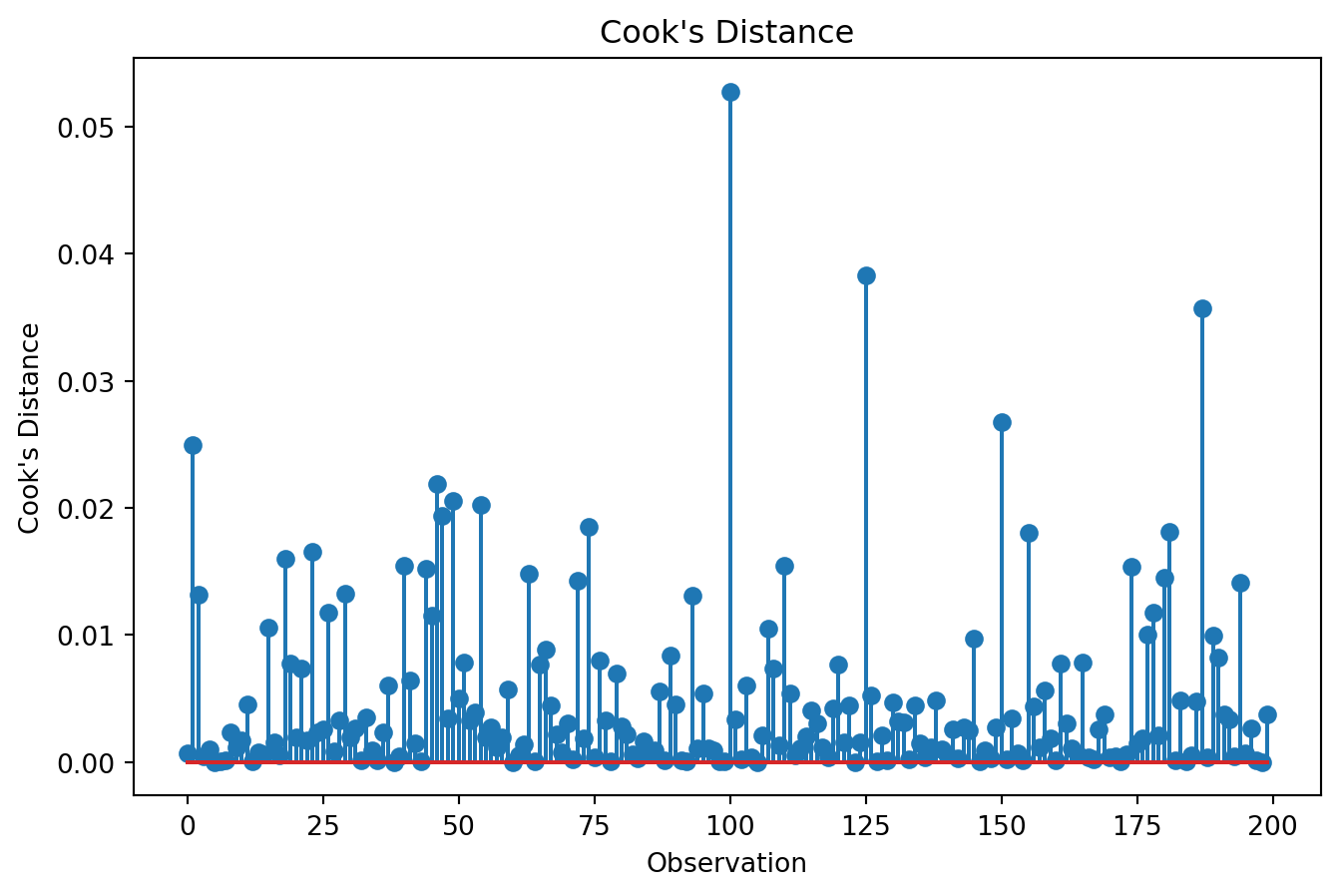
Are there influential observations?
Are the results robust to alternative specifications?
These questions form the foundation of empirical credibility.
Simulating crop yield data
We create a simple dataset to illustrate diagnostic procedures.
Most observations should have relatively small influence. A few unusually large values may indicate observations requiring further investigation.
Influential observations are not necessarily incorrect. However, they should always be examined carefully.
Step 6: Robustness checks
Credible research rarely depends on a single specification. Researchers often estimate alternative models.
Examples include:
Alternative variables
Replace one measure with another.
Alternative functional forms
Compare linear, log-linear, and log-log models.
Alternative samples
Estimate the model using the full sample, subsamples, or different time periods.
Alternative standard errors
Compare conventional OLS, robust standard errors, and Newey-West standard errors.
Results that remain stable across alternative specifications are generally more convincing.
Statistical significance versus economic significance
A statistically significant coefficient is not necessarily important.
Example 1
A coefficient implies a 0.001 percent increase in yield. The result is statistically significant, but the economic impact is trivial.
Example 2
A coefficient implies a 15 percent increase in yield. The result is economically important.
Researchers should evaluate both dimensions.
A practical credibility checklist
Before reporting regression results, ask:
Economic logic
Do the signs make sense?
Are magnitudes reasonable?
Statistical evidence
Are coefficients significant?
Are confidence intervals reasonable?
Diagnostics
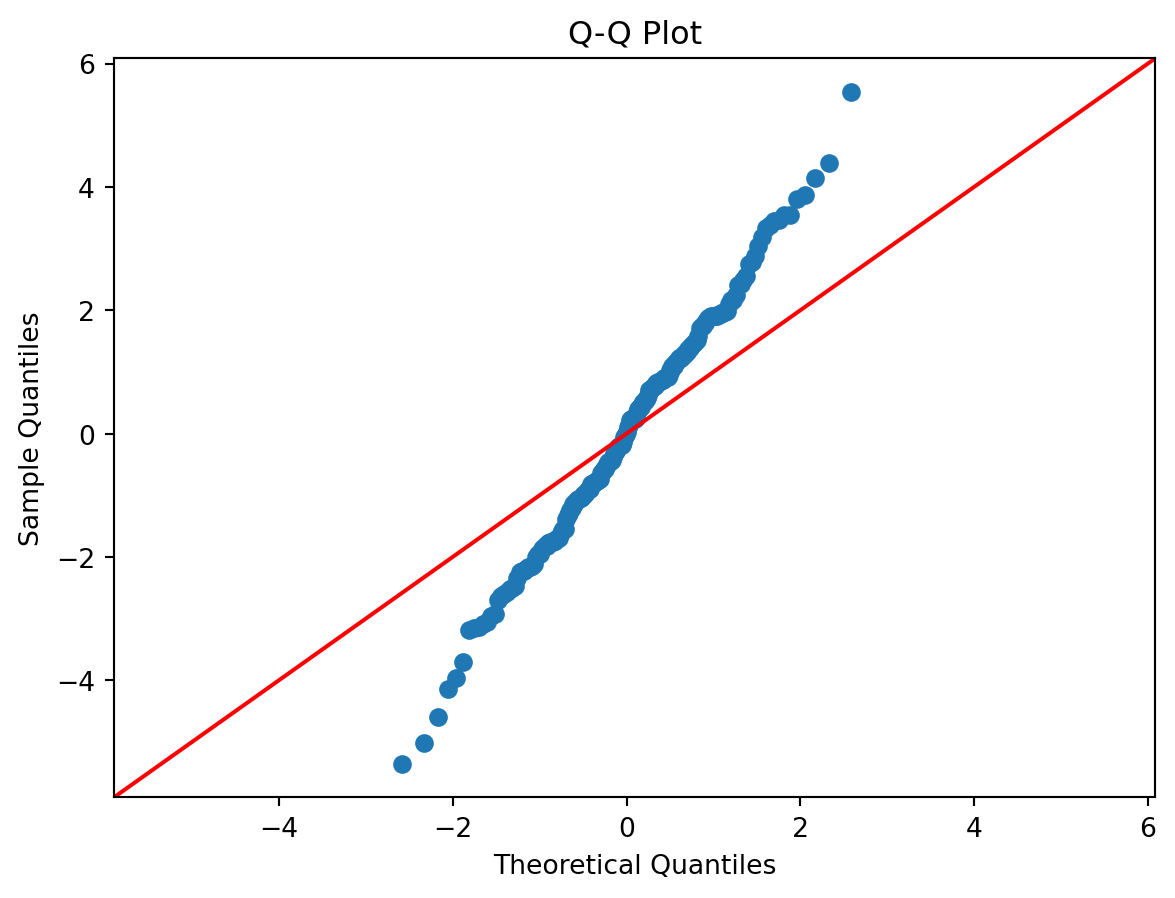
Do residuals appear random?
Is heteroskedasticity present?
Is autocorrelation present?
Model specification
Are important variables omitted?
Is the functional form appropriate?
Robustness
Do results survive alternative specifications?
If several answers are negative, conclusions should be interpreted cautiously.
TipGood empirical habit
Treat diagnostics as evidence, not as a checklist. A model is more credible when its results are statistically defensible, economically sensible, and robust to reasonable alternatives.
Common mistakes
Mistake 1: Focusing only on p-values
Significance alone does not establish credibility.
Mistake 2: Ignoring residuals
Residual analysis often reveals important model weaknesses.
Mistake 3: Assuming diagnostics are formalities
Diagnostics provide valuable information about model quality.
Mistake 4: Ignoring influential observations
A small number of observations can sometimes drive results.
Mistake 5: Confusing statistical significance with economic importance
The two concepts are related but distinct.
Key takeaways
Model diagnostics help evaluate empirical credibility.
Economic reasoning and statistical evidence should complement one another.
Residual plots reveal important information about model performance.
Q-Q plots help assess residual normality.
The Ramsey RESET test can identify possible misspecification.
Influential observations should be examined carefully.
Credible research requires more than statistically significant coefficients.
Looking ahead
This chapter concludes Part IV by showing how economists evaluate empirical credibility. In Part V, we shift our focus from explanation to prediction. We explore machine learning methods that are designed to maximize predictive accuracy, often sacrificing some of the interpretability emphasized in traditional econometric models.